Analysis Engine - Documentation
The analysis engine is the 'brain' of Jemos Clanker. Its main role is
to analyze a set of Java sources and to make available the results of
the analysis process to its clients. Those data are made available through
bean-like objects that contain either data and operations to retrieve
the required information. The most important of those objects, is
identified by the Amplimet, represented by the class
uk.co.jemos.clanker.impl.AmplimetImpl and whose contract is defined
by the uk.co.jemos.clanker.core.Amplimet interface. An Amplimet is
contained within a Thapter, identified by the class
uk.co.jemos.clanker.impl.ThapterImpl and whose contract is defined
by the uk.co.jemos.clanker.core.Thapter interface. A thapter is
the main 'analysis engine object' since it's the object which gets initialized
with the list of sources to analyze and filters to apply and which contains
the business methods to start the analysis engine.
Analysis Engine: main components
At high level, there are few major components, shown in the
picture below and about which follows a description.
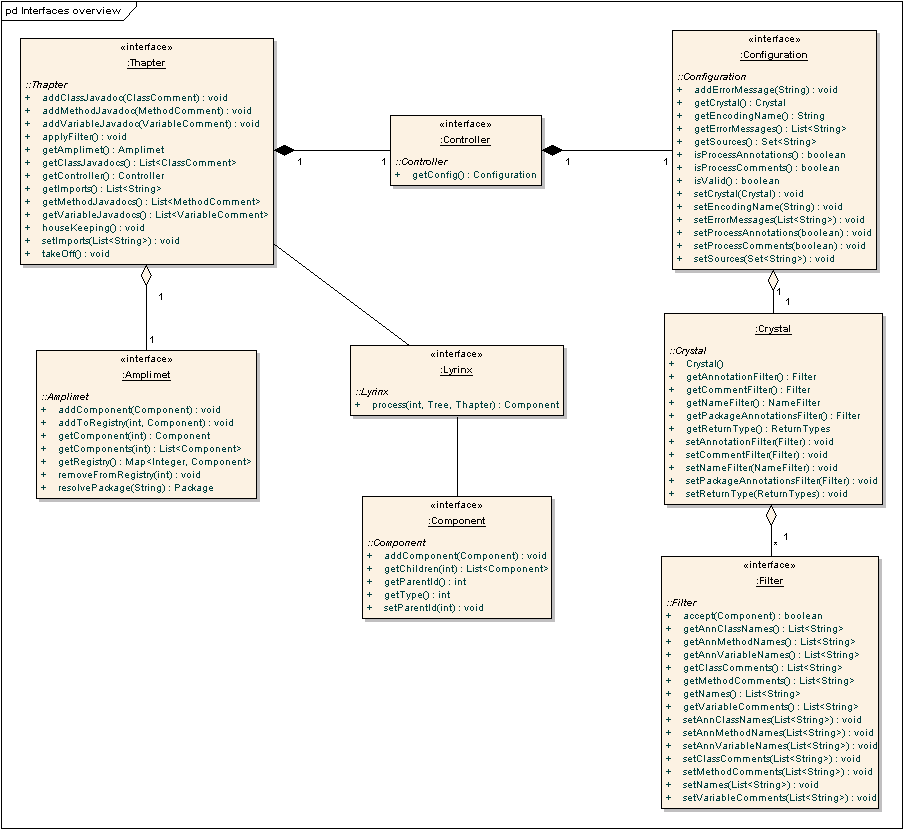
- Thapter. This is the main object in the analysis engine. Its
responsibilities are to coordinate the analysis activities and to
maintain an Amplimet (see below), which contains
the analysis results. A Thapter needs to be initialized with a
Controller which in turn needs to be created with
a Configuration object. Referring to the 'Well of Echoes'
series, from which the Thapter takes the name, a Thapter is an alien
construct that the heroin of this series made fly and then ever since
became an important anspect in winning the war for humans.
- Controller. A controller in the book series is a special artifact
that artisans can make move things thanks to the power of crystals, by
using the 'aura' manifested by those crystals. In this framework as in
the book, a controller is used to give 'life' to a Thatper (and Clankers
for that matter) and in order to be of any use, it must be created using
a configuration object.
- Configuration. A configuration object is created as first
step when using Jemos Clanker. It can be initialized with info like:
process/don't process Javadocs; process/don't process Annotations; I want
only classes with this particular Javadoc or Annotation; this is the
list of sources Clanker has to analyze, etc.
- Crystal. A crystal is an object containing all possible filters
that Jemos Clanker will use in order to 'filter' the analysis results.
The approach to set up filters is to create the desired filters first,
to set those filters in a Crystal object and to set the Crystal object
in a Configuration object.
- Filter. Filters are used to filter information. Currently only
three types of filters are supported, but nothing avoids you from creating
your own. All you need to do is to create a class which implements the
Filter interface. The filters currently supported allow you to select
only classes with specific Javadoc tags at class, method and instance
variable level and/or to select only those classes with specific Annotation
names at class, method and instance variable level. You can use those
filters separately or together. Jemos Clanker will handle the process
behind the scenes, returning those classes that at least match a filter
criteria. It is also possible to ask Jemos Clanker to return all classes,
even if filters were specified: in this case bean-like objects encapsulating
Class, Method, Instance Variables, etc will be returned but only with the
information defined in the filters (for the concepts of Class, Method, etc.
please refer to the 'Component' section below).
- Component. A component is another central concept in Jemos
Clanker. Each object implementing the 'Component' interface represents
a logical part in a Java source program. The logical parts currently
supported are: Classes, Methods, Instance Variables, Annotations,
Javadoc comments (at various level, like class, method and instance
variable), Packages, Local variables. When Jemos Clanker analysis engine
runs, it fills one or more of those components with the relevant information
that will then be available in a bean-like structure. The component are
related in a parent-child structure, so that a Package can have children
(typically classes), Classes can have children (methods, instance variables,
other classes) and so on. At runtime, Jemos Clanker fills an
Amplimet with the list of Packages, and then delegates
to Lyrinx the job of analyzing parts of source and to create
the related bean-like structures, flagging each one with its parent. It's
important to note that each Component, at the end of the process, must
contain attributes identifying the information specific to that component,
be these Java source info (like the list of parameters of exceptions for
a method), Javadoc info (like the list of Javadoc tags with their values),
Annotation info (like the annotation name, their attributes and values).
This makes very easy then to process the results in a script-based
framework (like Jelly for instance). In few words the analysis engine
is responsible for filling up nicely all the required information,
whereas the result engine is responsible to offer a set of tags
that make easy to launch the analysis tool and to use its results
afterwards.
- Amplimet. An amplimet is the object which external clients
will use when the analysis engine has finished the process. In the
book series, an amplimet is an extremely precious crystal, which
has been in a mine for thousands of years waiting for someone
to discover it and that, apparently is capable of guiding events.
Similarly, in this framework an Ampliment is the most precious
object available at the end of the process, since it's possible
to retrieve the list of analyzed packages from it and then, from
each package is possible to retrieve the list of classes and so
on. The Amplimet offers also methods to maintain the registry of
components. To facilitate the programmatic use of the parent/child
relationship at runtime, each component (except from a Package) must
be created setting in its state the unique id of its parent (we
assumed the hashcode of the parent object to be this unique id).
Analysis engine: starting the analysis process
Back to the top
Here follows a brief overview of the activities necessary to start
the analysis process. Please note that setting the list of Java
source to analyze in the ConfigurationImpl object is mandatory
but defining filters (and therefore a Crystal object) is not.
Additionally, users can specify whether
(if they set one or more filters) they want in return only the
classes matching those filters, or all the classes with only
the filtered information.

The takeOff() method of the Thapter class starts the
analysis process. Those are the activities that a client will need
to perform in order to initialize and start the analysis engine:
- Create a Configuration object. The default implementation
is uk.co.jemos.clanker.impl.ConfigurationImpl and the
contract is defined by the uk.co.jemos.clanker.core.Configuration
interface.
- Sets a collection of paths (represented as String objects)
pointing to Java sources. This is the list of Java sources
that the analysis engine will analyze. This step is
mandatory, since the analysis wouldn't make sense if
there were no source to analyzie :)
- The client can set a flag to tell the analysis engine if
it should process Javadocs. The default is true and this is
not a mandatory attribute.
- The client can set a flag to tell the analysis engine if
it should process Annotations. The default is true and this is
not a mandatory attribute.
- Clients can specify one or more Javadoc/Annotation filters, by
creating objects of the filter classes, whose contract is defined
by the uk.co.jemos.clanker.core.Filter interface. The only
filters supported at the moment are: Javadoc, Annotation and Name
filters. These are represented by classes located in the
uk.co.jemos.clanker.filters package
- If any filter was created, then clients should create an
instance of the uk.co.jemos.clanker.filter.Crystal class,
and set those filters as attributes in the Crystal class. The Crystal
class then should be set as attribute in the ConfigurationImpl object.
object in the Configuration object. Filters are not mandatory and
if not specified, all Javadocs and Annotations will be taken into
consideration. Additionally, if filters were set, clients have got
the opportunity to ask the analysis engine if they want it to
return all classes (although only with the data matching the filters)
of if they want it to return only the classes matching at least one
of the matching filters. This is accomplished by setting the
returnType attribute of the Crystal object, represented
by an enumeration (a new concept in Java 5). The possible values
for this attributes are either: ALL or CLASSES, where
the former asks for all classes (although the Javadocs and Annotations
contained within will match the filters selection) and the latter
asks to return only the classes for which at least one match was
found.
- Create a Controller, represented by an instance of the
class uk.co.jemos.clanker.impl.ControllerImpl, whose
contract is defined by the uk.co.jemos.clanker.core.Controller
interface. A controller must be initialized with the instance of
a ConfigurationImpl created above
- Create an instance of the uk.co.jemos.clanker.impl.ThapterImpl
class, whose contract is defined by the
uk.co.jemos.clanker.core.Thapter interface, initializing it
with the ControllerImpl instance created above.
- Starting the Thapter by invoking its takeOff() method
Below is an example of how the HeartBitTag class initializes
and invokes the analysis process, following the steps identified above:
//Prepares the configuration object
ConfigurationImpl config = new ConfigurationImpl();
//Sets the filters if any were set up by the children
Crystal crystal = new Crystal();
//javadocFilter is an instance of the CommentFilter class
if (null != javadocFilter) {
crystal.setCommentFilter(javadocFilter);
}
//annotationFilter is an instance of the AnnotationFilter class
if (null != annotationFilter) {
crystal.setAnnotationFilter(annotationFilter);
}
//Sets the returnType attribute of the Crystal class
if (getType().toLowerCase().equals("class")) {
//I want only classes matching the filters
crystal.setReturnType(ReturnTypes.CLASSES);
} else {
//Get me all classes but the Javadoc/Annotation/Class names
//must match the filters
crystal.setReturnType(ReturnTypes.ALL);
}
//Sets the crystal object in the configuration object
config.setCrystal(crystal);
//Sets the sources to analyze in the configuration object
config.getSources().addAll(this.getSources());
//Sets the flag whether to process Javadoc and/or Annotations
config.setProcessComments(this.isProcessJavadocs());//boolean
config.setProcessAnnotations(this.isProcessAnnotations());//boolean
try {
//Creates the controller and initializes it with the
//configuration object
Controller controller = new ControllerImpl(config);
//Prepares the Thapter and initializes it with the controller object
Thapter thapter = new ThapterImpl(controller);
buff.append("[HeartBit]Launching the thapter...\n");
//Launches the thapter
thapter.takeOff();
buff.append("[HeartBit]Thapter ended the execution. Retrieving the amplimet...\n");
//The Thapter has filled the entry point for the result in the Amplimet
//object
Amplimet amplimet = thapter.getAmplimet();
//Here it retrieves the packages from the Ampliment and
//from each package it retrieves the list of classes
packages.addAll(amplimet.getComponents(COMPONENT_TYPE_PACKAGE));
Package p = null;
for (Component pkg: packages) {
p = (Package)pkg;
buff.append("[HeartBit]Package: " + p.getPackageName());
classes.addAll(p.getChildren(COMPONENT_TYPE_CLASS));
}
//Sets the data in the context and invokes the output script
getContext().setVariable("classes", this.getClasses());
getContext().runScript(outputF, output);
output.flush();
} catch (ConfigurationException e) {
throw e;
} catch (ThapterException e) {
throw e;
} catch (IOException e) {
throw e;
}
How does the analysis process work?
Back to the top
The analysis process delegates to the Java Compiler API the
parsing and externalization of the Java source files. The
method which starts the analysis process is takeOff()
which simply invokes two methods:
- wakeTheAmplimet
- applyFilters
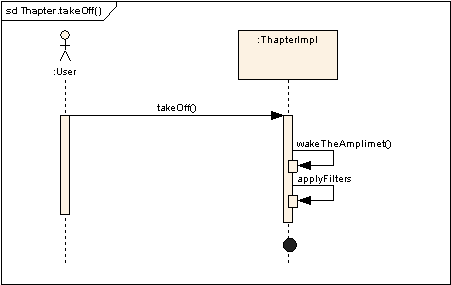
The wakeTheAmplimet() method is shown below:
Back to the top
As mentioned earlier, Jemos Clanker delegates to the JDK parser
the job of parsing a Java source and to make available objects
each one identifying a logical part of a Java source file. The
JDK parser divides a Java source in its logical parts (the imports,
the package declaration, the class declarations, method and parameters,
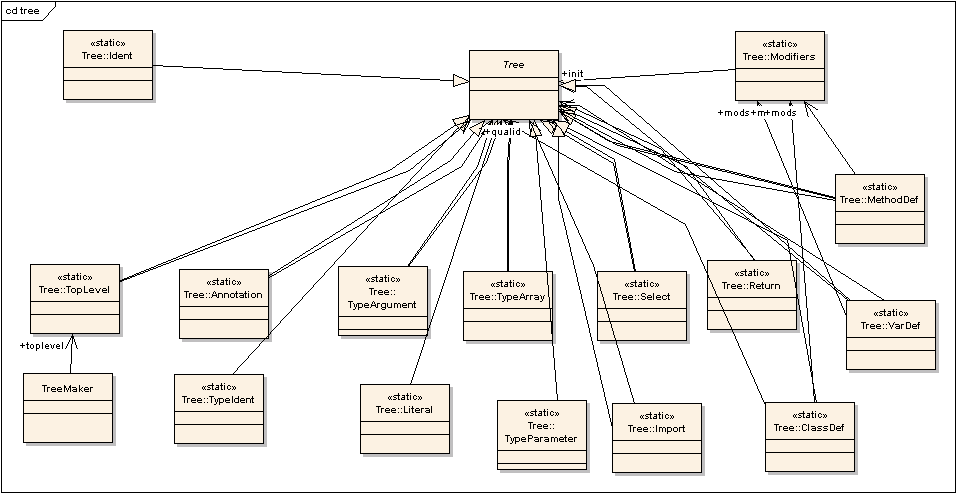
exceptions, annotations, etc.). Each one of these logical parts is
set in a class child of the com.sun.tools.javac.tree.Tree class.
Below you can see a class diagram of some of the children of the Tree
class (the diagram is a bit messy because I had to squeeze all the
Tree objects so as to have all of them in one page):
Where a class gets processed: the fillTheAmplimet() method
Back to the top
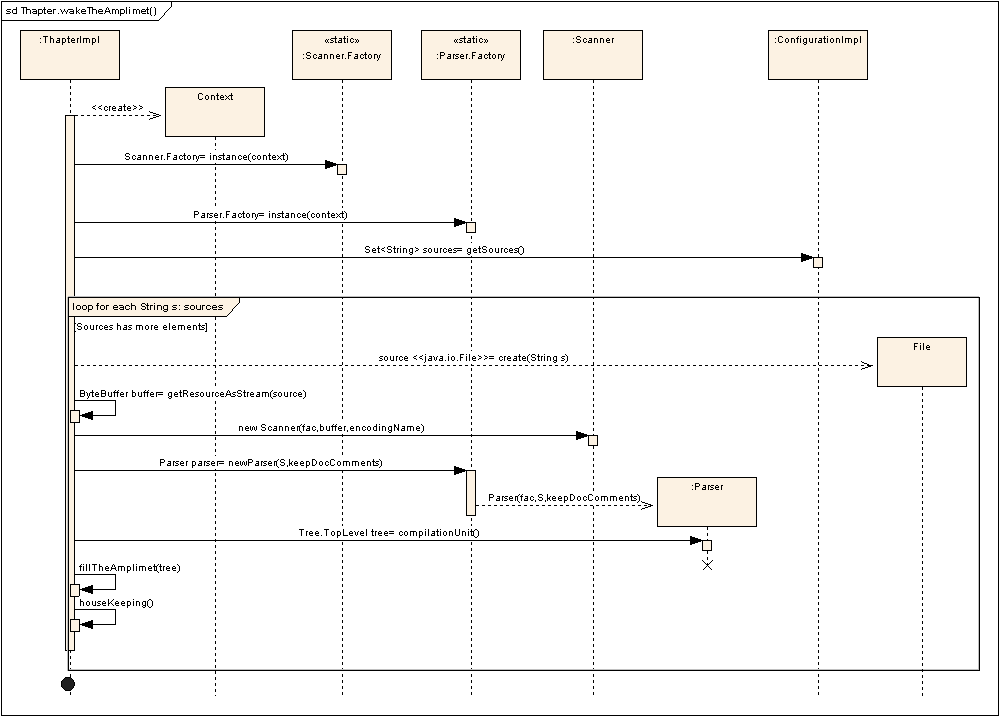
All the wakeTheAmplimet method does is to loop through each
of the Java source paths set in the sources collection set
in the ConfigurationImpl object. For each of these sources,
it creates a java.io.File object which is then converted
in a java.nio.ByteBuffer object. This ByteBuffer object
is then passed as argument to the constructor of the
com.sun.tools.javac.Scanner class which in turn is passed
as argument to the com.sun.tools.javac.Parser.Factory class
in order to obtain a new com.sun.tools.javac.Parser object. The
Parser is actually the class which performs the source analysis and
then externalizes a class in its logical parts in a
com.sun.tools.javac.tree.Tree object with all its sub-trees.
Once the Tree object is created, which happens for each Java source,
the fillTheAmplimet(Tree) method is invoked. Below there is
a sequence diagram which illustrates what this method does.

Here what happens:
- If a Package instance already exist (packages are unique),
we just use it, otherwise a new one is created and set in the
Amplimet. The Amplimet maintains a collection of Packages
being processed, that's why it's the main object returned by
the analysis process. Clients should iterate over the collection
of packages and for each package should retrieve the children
(classes) and so on in a recursive way until all the components
of interest have been dealt with.
- The fillTheAmplimet(TopLevel Tree) method receives as parameter
a TopLevel object (static inner class of com.sum.tools.javac.tree.Tree),
containing an 'objectized' version of a Java class. By 'objectized' I mean
a division of a class' logical parts into subclasses of Tree. Those
logical parts encapsulate Javadoc comments, the different elements of
a class (methods, instance variables, inner classes, etc), Annotation
definitions, etc.
- The method loops through all the different parts of the Tree and
delegates their analysis and processing to ad-hoc
processors (Lyrinx). The order in which Tree components are
contained in the TopLevel object is the following:
- Package definitions
- Import declarations
- Javadoc comments
- Class members (class, method, instance variable
definitions)
We've already seen how Packages are processed. Since this method
is invoked for each Java source, we may be quite relaxed at the
idea of storing the list of imports and Javadoc definitions in
the ThapterImpl class itself, so that processors will be able
to refer to it during the processing. The execution of the
fillTheAmplimet method is not thread-safe. This means that
it is not possible to invoke the same method for two different
classes simultaneously. Each execution has to do with one class
at the time, since class-specific information like imports and
Javadocs are stored as instance variables. Kept the ordering
process correct though, this approach works very nicely, since
an instance of ThapterImpl is passed as parameter to
each Tree processor.
So this method stores all the imports in a collection declared
as instance variable (which gets cleared before each invocation);
it then delegates to the Javadoc processor the Javadoc processing
(the processor will store as instance variables of ThapterImpl the
class, methods and instance variables Javadocs for other processor
to look at, and similarly to what happened with imports, cleared
before each iteration). Once package, class and Javadocs
have been 'externalized' to Javabean-like structures, this method
retrieves the right processor for the Tree being processed (in this
case a ClassLyrinx) and delegates to this processor the class'
externalization. At the end of the processing of the ClassLyrinx class,
a uk.co.jemos.clanker.components.Clazz object has been filled
with all class-related and class-members' related information and
it is then added as child of the Package object through the
addComponent(component) method.
Applying filters
Back to the top
Filters are used in one of two ways:
- To restrict the Javadoc/Annotation info returned by the analysis process
- To select only those classes which contain at least one matching
criteria for Javadoc or Annotation or name
Filters are specified by creating instances of classes implementing the
uk.co.jemos.clanker.filters.Filter interface. Currently Jemos
Clanker supports only three kind of filters:
- Javadoc filters
- Annotation filters
- Name filters
Filters are specified
before starting the analysis process, by
creating filter objects, a crystal object and by setting those filters
as instance variables in a crystal. Then the crystal is set as instance
variable of the ConfigurationImpl class so that it participates in
the Thapter initialization. You can refer to the above
paragraph
to refresh how filters and the Crystal object are created.
Here follows how the Thapter.applyFilters() method works:

Here what happens:
- The first thing the method determines is if it has to
apply class exclusion. If the client creates a Crystal
object and set the returnType instance variable
to the value of uk.co.jemos.clanker.util.Constants.ReturnTypes.CLASSES
(which is an enumeration value) it means that class exclusion
has been turned on. In this case, only the classes matching
at least one filter criteria will be returned. If class
exclusion has been turned off then all classes will be
returned, but those will contain only the values specified
in the filters.
- The method determines if any Javadoc and/or Annotation filters
were setup, setting some boolean flags to indicate that. If no
filters were applied, it returned immediately.
- The method then retrieves all the analyzed packages from
the Amplimet object filled in during the execution
of the wakeTheAmplimet() method. Since the appliFilters()
method is invoked at the end of the analysis process, the Amplimet
contains all the Java sources externalized.
- For each Package, the method retrieves all classes and
apply Javadoc and/or Annotation filters, depending on which
of those were set up. The result of applying those filters
is that Javadocs and/or Annotations not matching the
filters will be removed from the collections containing
them. If class exclusion was turned on, the method
checks if any values matching the filters have been found.
If this is not the case, the class is marked for deletion
(i.e. it will be removed from the value returned to the
client).
- Similarly to what the method performed with the Package
happens also for each class object. For each one of them
in fact, the method retrieves all methods and instance
variables and applies the filters with the same logic
explained in the point above. The only difference here
is that, even if class exclusion was turned on but
the filter at class level found a valid class (i.e.
at least one matching criteria), even if the method
and/or instance variable filtering haven't produced
any results the class will be kept and returned to
the client.
- At the end of the process, if the class has to
be removed, this is removed from the collection
of the Package children and from the
registry of components maintained in the
Amplimet.
